SGLang 模型推理部署与二次开发全景指南
面向从 FastDeploy 迁移到 SGLang 的工程实践:讲清楚 SGLang 的特性、运行时结构、DeepSeek/GLM 推理链路、Cache 管理、集中式部署、Prefill/Decode 分离部署,以及如何进入源码做模型、缓存、调度和网关层扩展。
- SGLang 是一个面向大模型推理服务的高性能运行时,核心组合是 OpenAI 兼容 API、动态调度、RadixAttention 前缀缓存、丰富 attention backend、DeepSeek/GLM 等大模型专项优化,以及 PD 分离式部署能力。
- 如果你从 FastDeploy 转过来,迁移重点不是“换一个启动命令”,而是把服务拆成四层:入口协议层、调度层、模型执行层、KV Cache/传输层;SGLang 在后两层给了更多可调参数和源码扩展点。
- DeepSeek V3/V3.1/R1 的关键是 MLA、MoE、FP8/DeepGEMM、DP Attention、EAGLE;DeepSeek V3.2 与 GLM-5 进一步引入 DSA 稀疏注意力,SGLang 文档给出了专门部署命令和 kernel 选择策略。
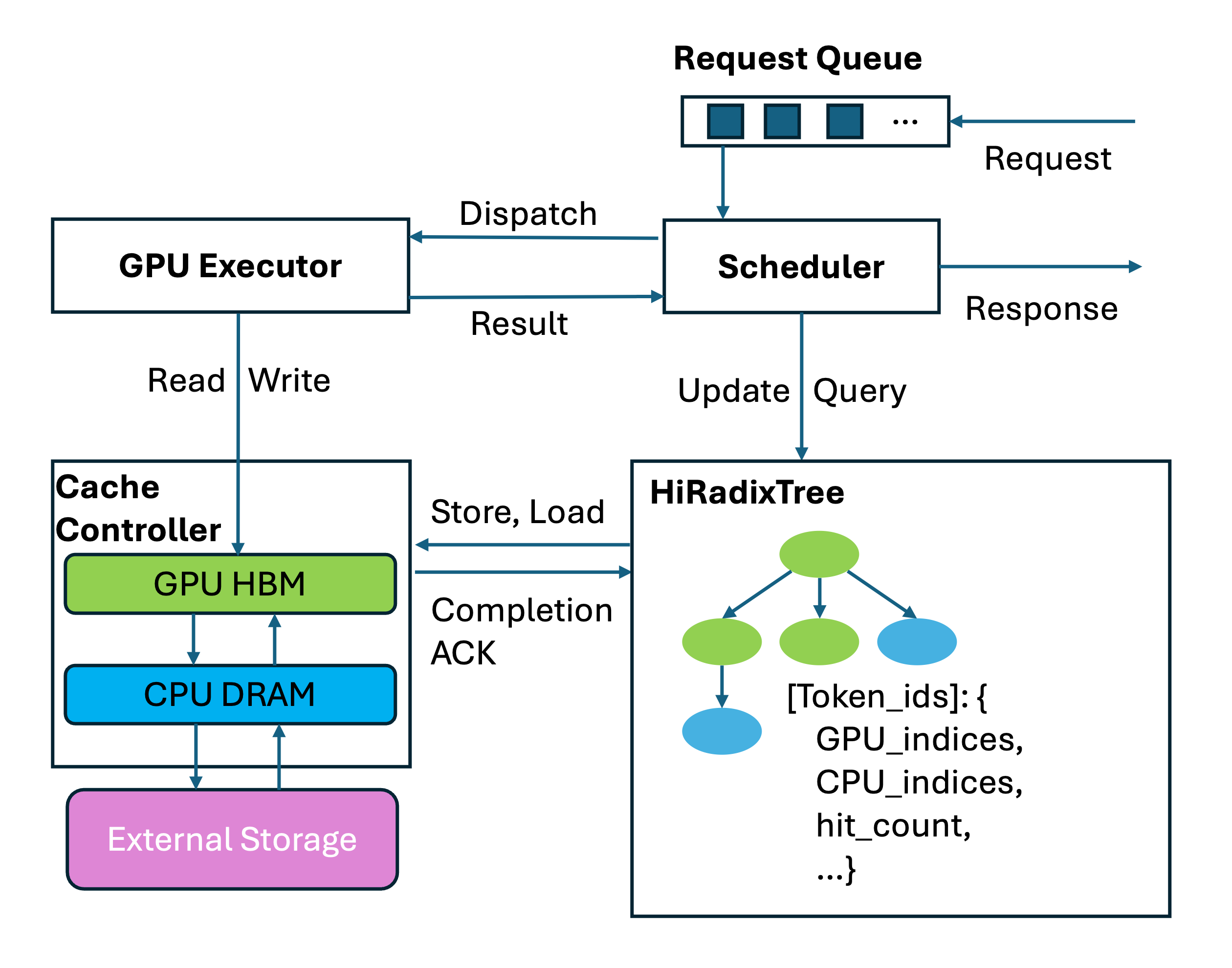
- Cache 管理是 SGLang 的灵魂:L1 GPU KV pool + RadixCache 做本地前缀复用;HiCache 把缓存扩展到 L2 host memory 与 L3 分布式存储;PD 模式再把 prefill 生成的 KV 通过 Mooncake/NIXL/Ascend 传到 decode worker。
- 集中式部署适合快速上线和中小规模服务;PD 分离适合长上下文、高并发、prefill 与 decode 干扰明显的生产场景,但会引入传输后端、bootstrap、router、缓存一致性和观测复杂度。
1. 从 FastDeploy 迁移到 SGLang:先换脑图,再换命令
很多迁移失败不是因为 SGLang 难用,而是还按“单进程模型服务”的方式理解它。SGLang 的设计更像一个推理操作系统:它把请求接入、tokenization、调度、模型 forward、cache 分配、KV 迁移、detokenization、router 负载均衡拆成清晰模块。
flowchart LR
A["FastDeploy 迁移视角"] --> B["API 兼容层"]
A --> C["模型权重与 tokenizer"]
A --> D["并行与显存策略"]
A --> E["缓存复用策略"]
A --> F["集群与网关策略"]
B --> B1["OpenAI /generate /embeddings"]
C --> C1["HF repo 或本地路径"]
D --> D1["TP / DP / EP / PP / DP Attention"]
E --> E1["RadixCache / HiCache / cache-aware routing"]
F --> F1["SGLang Router / PD / 多 worker"]
| 迁移项 | FastDeploy 里常见关注点 | SGLang 对应方式 | 迁移建议 |
|---|---|---|---|
| 服务入口 | HTTP/RPC 服务、模型名、采样参数 | sglang.launch_server 暴露 OpenAI-compatible API;router 可接多个 worker |
优先改客户端 base_url,不要一开始重写业务 SDK。 |
| 模型加载 | 本地权重、模型配置、量化格式 | --model-path/--model 指向 HF repo 或本地目录;支持 safetensors、gguf、bitsandbytes、fastsafetensors 等 load format |
生产建议先离线下载权重,固定 revision,记录 commit 与启动参数。 |
| 并行策略 | 多卡切分、张量并行、流水线 | --tp、--dp、--ep、--pp、--enable-dp-attention |
小模型先用 TP/DP;DeepSeek 大模型重点评估 DP Attention 与 EP。 |
| 显存与吞吐 | batch、max tokens、OOM | --mem-fraction-static、--max-running-requests、--chunked-prefill-size、--cuda-graph-max-bs |
以压测日志里的 token usage、queue req、TTFT/TPOT 为准,不靠感觉调参。 |
| 缓存复用 | prefix cache、KV cache 容量 | RadixAttention/RadixCache 默认本地复用;HiCache 扩展到 host 与分布式存储 | 多轮对话、固定系统提示、RAG 模板、长文档 QA 是缓存收益最大的场景。 |
| 大规模服务 | 网关、LB、容错、扩缩容 | SGLang Model Gateway / Router;支持 regular worker、PD worker、gRPC、cache-aware 策略 | 先集中式上线,再按瓶颈决定是否拆 PD;不要过早把架构复杂化。 |
2. SGLang 的核心特性
OpenAI 兼容服务
支持 chat completions、completions、embeddings、vision、rerank、classify 等入口。客户端可用 OpenAI Python SDK,把 base_url 指向 SGLang。
RadixAttention
用 radix tree 组织前缀 KV,复用共享 prompt 的已计算缓存。它不是简单哈希缓存,而是按 token 前缀做最长匹配、节点分裂与 eviction。
Prefill/Decode 分离
把计算密集的 prefill 和内存带宽密集的 decode 拆到不同 worker,降低 prefill 对 decode latency 的干扰。
DeepSeek/GLM 专项优化
覆盖 MLA、DSA、MoE、FP8、DeepGEMM、DP Attention、EAGLE speculative decoding、reasoning/tool parser 等关键路径。
HiCache 层级缓存
GPU memory 作为 L1,host memory 作为 L2,Mooncake/HF3FS/NIXL/AIBrix 等作为 L3,适合长上下文与跨实例缓存复用。
源码扩展友好
模型实现集中在 srt/models,cache 在 srt/mem_cache,调度在 srt/managers,PD 在 srt/disaggregation。
重要能力矩阵
| 能力 | 主要参数/模块 | 何时使用 | 注意点 |
|---|---|---|---|
| Tensor Parallel | --tp/--tp-size |
单模型放不进一张卡,或需要多卡分摊计算 | TP 越大通信越重;跨节点 TP 要关注网络与 NCCL。 |
| Data Parallel | --dp、router 多 worker |
模型能放进每组 GPU,希望提升吞吐 | 官方文档更推荐用 Model Gateway 做数据并行入口。 |
| DP Attention | --enable-dp-attention --dp N |
DeepSeek 类 MLA/MoE 高并发场景,KV 容量成为瓶颈 | 不适合低延迟小 batch 场景,可能增加单请求延迟。 |
| Expert Parallel | --ep、--moe-a2a-backend |
MoE 大模型,专家层通信成为主要瓶颈 | 需要评估 DeepEP、网络拓扑和 expert load balance。 |
| Quantization | --quantization、--kv-cache-dtype |
降低显存、提升并发或匹配 FP8/NVFP4 checkpoint | DeepSeek 官方 FP8 权重不需要再加 --quantization fp8。 |
| Speculative Decoding | --speculative-algorithm EAGLE |
DeepSeek/GLM 等支持 MTP 或草稿模型时提升 decode | 要配合 batch size、attention backend、CUDA Graph 捕获范围调。 |
| Structured Output | xgrammar / outlines / llguidance | JSON、正则、函数调用、受限生成 | 会引入 grammar 编译和调度开销,需压测。 |
| Observability | --enable-metrics、--enable-trace、profiler endpoints |
生产压测、问题定位、容量规划 | PD 模式 prefill 与 decode profiler 必须分开抓。 |
3. SGLang 运行时整体架构
SGLang 的后端通常称为 SRT。一个最小服务包括 HTTP/OpenAI 入口、TokenizerManager、Scheduler、TP worker / ModelRunner、DetokenizerManager、KV cache 与 attention backend。请求不是“直接调用模型”,而是被拆成 tokenization、排队、prefill/extend、decode、采样、detokenize、streaming 输出。
flowchart TD
Client["Client / OpenAI SDK / curl"] --> HTTP["HTTP Server<br/>OpenAI-compatible endpoints"]
HTTP --> Tok["TokenizerManager<br/>text/image/audio -> token ids / embeddings"]
Tok --> Sched["Scheduler<br/>waiting queue / running batch / policies"]
Sched --> Cache["KV Cache Manager<br/>ReqToTokenPool + TokenToKVPool + Radix/HiCache"]
Sched --> Worker["TP Worker"]
Worker --> Runner["ModelRunner<br/>forward_extend / forward_decode"]
Runner --> Attn["Attention Backend<br/>FA3 / FlashInfer / TRTLLM / FlashMLA / DSA"]
Runner --> Model["Model Implementation<br/>srt/models/*.py"]
Model --> Sample["Sampler / logits processor / grammar"]
Sample --> Detok["DetokenizerManager"]
Detok --> HTTP
HTTP --> Client
源码入口图
这些路径是你二开 SGLang 时最常看的“地标”。
python/sglang/launch_server.py python/sglang/srt/entrypoints/http_server.py python/sglang/srt/managers/tokenizer_manager.py python/sglang/srt/managers/scheduler.py python/sglang/srt/model_executor/model_runner.py python/sglang/srt/mem_cache/ python/sglang/srt/disaggregation/ python/sglang/srt/models/调度器初始化顺序
从当前源码看,Scheduler 会解析参数、初始化并行状态、启动模型 worker、构建 KV cache、注册 HiCache draft pool、初始化 chunked prefill、建立调度策略,最后进入普通或 overlap event loop。
关键行来自 python/sglang/srt/managers/scheduler.py:Scheduler 在初始化阶段调用 kv_cache_builder.build_kv_cache(...),把 req_to_token_pool、token_to_kv_pool_allocator 和 tree_cache 接到调度链路。
并行体系:TP、DP、EP、PP、DP Attention 怎么选
| 策略 | 切分对象 | 适合场景 | 启动参数 |
|---|---|---|---|
| TP Tensor Parallel | 矩阵权重、attention heads、MLP 等按 GPU 切 | 单模型太大;DeepSeek/GLM 大 checkpoint 常用 | --tp 8、跨节点加 --nnodes/--node-rank/--dist-init-addr |
| DP Data Parallel | 多份模型副本处理不同请求 | 吞吐优先、模型可复制 | --dp 2 或 router 多 worker |
| DP Attention | attention KV cache 按 DP 分组,不在所有 TP rank 复制 | DeepSeek 类 MLA 高并发,KV cache 容量限制明显 | --enable-dp-attention --dp 8 |
| EP Expert Parallel | MoE experts 分布到不同 GPU | DeepSeek/GLM/Kimi/Qwen MoE 大模型 | --ep 8、--moe-a2a-backend deepep |
| PP Pipeline Parallel | Transformer layers 分段 | 模型深、显存压力大或多节点流水线 | --pp 2、可结合 dynamic chunking |
Attention backend 选择
SGLang 默认会按硬件与模型架构自动选择 backend,但生产调优时你需要知道边界条件:MHA 模型常见 backend 有 FlashInfer、FA3、FA4、Triton、TRTLLM MHA;MLA 模型有 FlashInfer MLA、FlashMLA、Cutlass MLA、TRTLLM MLA、FA3、Triton;DeepSeek V3.2/GLM-5 的 DSA 又有 flashmla_sparse、flashmla_kv、fa3、trtllm、tilelang、aiter 等子 backend。
--page-size 越大,metadata 和 I/O 更友好,部分 backend 也要求固定页大小;但 prefix cache 只能匹配完整 page,短 prompt 或细粒度共享场景会降低命中率。想最大化 prefix reuse 用小 page;想压榨 kernel/存储吞吐时再上大 page。
4. SGLang 对大语言模型的支持情况
截至本报告使用的官方仓库快照,SGLang 文档把模型支持分成文本生成、多模态、embedding/rerank/classify、specialized 与扩展模型。文本生成支持范围已经覆盖 DeepSeek、Kimi、GPT-OSS、Qwen、Llama、Mistral、Gemma、Phi、MiniCPM、OLMo、MiniMax、Command、DBRX、Grok、ChatGLM、GLM-4、InternLM、Baichuan、XVERSE、ERNIE、Nemotron 等大量模型族。
| 模型族 | SGLang 支持重点 | 典型模型 ID | 工程关注点 |
|---|---|---|---|
| DeepSeek V3 / V3.1 / R1 | MLA、MoE、FP8、DeepGEMM、DP Attention、EAGLE、reasoning/tool parser | deepseek-ai/DeepSeek-R1deepseek-ai/DeepSeek-V3-0324 |
H200/B200/MI300X/H20/A100/NPU 等硬件下参数差异大,先按官方 DeepSeek usage 文档起步。 |
| DeepSeek V3.2 / GLM-5 | DSA 稀疏注意力、IndexCache、MTP/EAGLE、PD 示例 | deepseek-ai/DeepSeek-V3.2-Expzai-org/GLM-5-FP8 |
DSA backend 自动选择但可手动指定;GLM-5 共享 V3.2 多数部署方式。 |
| GLM-4.5 / GLM-4.6 / GLM-4.7 | FP8、多卡 TP、EAGLE、reasoning parser、tool call parser、thinking budget | zai-org/GLM-4.6-FP8 |
GLM-4.7 tool parser 用 glm47;GLM-4.5/4.6 用 glm45。 |
| Qwen / Llama / Kimi / MiniMax | 常规 MHA/GQA、MoE、reasoning、tool calls、部分多模态与长上下文 | Qwen/Qwen3-30B-A3Bmeta-llama/Llama-4-Scout... |
优先查 supported models 与 basic usage,注意 chat template 和 parser。 |
| 多模态模型 | Qwen-VL、DeepSeek-VL2/OCR、GLM-4.5V、Gemma 3、LLaVA、MiniCPM-V、Qwen3-ASR 等 | Qwen/Qwen3-VL-235B-A22B-Instructzai-org/GLM-4.5V |
关注 --enable-multimodal、--mm-process-config、bidirectional attention、显存限制。 |
| Transformers fallback | 未原生实现的 decoder-style 模型可回退到 Transformers backend | 任意符合条件的 HF 模型 | 需要模型 attention 支持 ALL_ATTENTION_FUNCTIONS 并声明 _supports_attention_backend。 |
DeepSeek 推理结构:MLA / MoE / DP Attention / EAGLE
DeepSeek V3/R1 类模型在 SGLang 中不是普通 Llama 路径。它的重点是 MLA 减少 KV cache 体积,MoE 提供大参数容量但只激活部分专家,FP8/DeepGEMM 提升矩阵乘效率,DP Attention 解决高并发下 KV cache 被 TP rank 复制的问题,EAGLE/MTP 用草稿 token 减少 decode 步数。
flowchart TD
T["Input tokens"] --> E["Embedding + positions"]
E --> L1["Transformer Layer x N"]
L1 --> MLA["MLA / DSA Attention<br/>RadixAttention wrapper"]
L1 --> MOE["MoE experts<br/>routing + all-to-all"]
MLA --> KV["KV / latent KV cache<br/>GPU pool + prefix tree"]
MOE --> N["Norm + residual"]
N --> H["Hidden states"]
H --> Head["LM Head / logits"]
Head --> Sample["Sampler / parser / grammar"]
Sample --> Out["Next token"]
Out -->|loop| L1


DeepSeek V3/R1 集中式启动参考
python3 -m sglang.launch_server \
--model-path deepseek-ai/DeepSeek-R1 \
--tp 8 \
--trust-remote-code \
--host 0.0.0.0 \
--port 30000 \
--mem-fraction-static 0.90 \
--enable-metrics \
--enable-cache-reportDeepSeek V3.2 / GLM-5 推荐思路
DeepSeek V3.2 通过 DSA 针对长上下文做稀疏注意力优化;GLM-5 也使用 DSA 结构,因此官方文档说明 GLM-5 可以复用 DeepSeek V3.2 的大部分部署方式,主要差异在 reasoning parser 和 tool parser。
# DeepSeek V3.2/GLM-5: TP + DP Attention
python -m sglang.launch_server \
--model deepseek-ai/DeepSeek-V3.2-Exp \
--tp 8 \
--dp 8 \
--enable-dp-attention
# GLM-5: 替换模型,并使用 GLM parser
python -m sglang.launch_server \
--model zai-org/GLM-5-FP8 \
--tp-size 8 \
--dp-size 8 \
--enable-dp-attention \
--tool-call-parser glm47 \
--reasoning-parser glm45GLM 推理结构与启动重点
GLM-4.5/4.6/4.7 与 GLM-5 在 SGLang 中都已经有官方 usage。GLM-4.5/4.6 FP8 可用 8xH100/H200 启动;可通过 EAGLE speculative decoding 提速;thinking budget 可通过自定义 logit processor 控制。GLM-5 则共享 DeepSeek V3.2/DSA 路径。
# GLM-4.6 FP8 基础启动
python3 -m sglang.launch_server \
--model zai-org/GLM-4.6-FP8 \
--tp 8
# GLM-4.6 + parser + EAGLE + thinking budget 支持
python3 -m sglang.launch_server \
--model-path zai-org/GLM-4.6-FP8 \
--tp-size 8 \
--tool-call-parser glm45 \
--reasoning-parser glm45 \
--speculative-algorithm EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4 \
--mem-fraction-static 0.9 \
--served-model-name glm-4.6-fp8 \
--enable-custom-logit-processor--reasoning-parser、--tool-call-parser、chat template 和客户端协议一起验收。
5. Cache 管理模块:从 KV pool 到 RadixCache 再到 HiCache
LLM 推理中的缓存不是“可选优化”,而是决定吞吐、延迟和显存容量的核心系统。SGLang 的缓存层可以按三个层级理解:请求到 token slot 的映射、token slot 到实际 K/V tensor 的内存池、前缀匹配和跨层级复用的 cache controller。
flowchart TD
Req["Req<br/>origin_input_ids + output_ids"] --> RTP["ReqToTokenPool<br/>req_pool_idx -> token slots"]
RTP --> Alloc["TokenToKVPoolAllocator<br/>alloc/free KV slots"]
Alloc --> KVPool["TokenToKVPool<br/>per-layer K/V tensors"]
Req --> Radix["RadixCache<br/>token prefix -> KV indices"]
Radix --> Match["match_prefix<br/>longest prefix hit"]
Radix --> Insert["cache_finished_req / insert"]
Radix --> Evict["evict<br/>LRU / LFU / FIFO / priority..."]
KVPool --> Attn["Attention backend reads KV"]
5.1 本地 GPU KV cache:两个 pool + 一个 tree
| 组件 | 源码位置 | 职责 | 二开关注点 |
|---|---|---|---|
| ReqToTokenPool | srt/mem_cache/memory_pool.py |
给每个请求分配 req_pool_idx,维护 request 到 token slots 的二维映射 |
并发请求上限、chunked prefill 复用 request slot、decode 侧 prealloc。 |
| TokenToKVPoolAllocator | srt/mem_cache/allocator.py |
为 extend/decode 分配 KV token slots,满了时触发 eviction 或 retract | OOM、碎片、page allocation、decode 每步增量分配。 |
| KV Pool | srt/mem_cache/memory_pool.py |
真实 K/V tensor 存储,按 MHA/MLA/Mamba/SWA 等形态有不同实现 | KV dtype、FP8/FP4、MLA latent KV、hybrid attention。 |
| RadixCache | srt/mem_cache/radix_cache.py |
用 token prefix 查找最长 KV 前缀,结束请求时插入,按策略驱逐 | extra_key 隔离 LoRA/版本/RAG 上下文;page_size 影响命中。 |
| Cache Builder | srt/mem_cache/kv_cache_builder.py |
根据模型、server args、并行组创建 req pool、KV allocator、tree cache | 新增 cache 类型、禁用条件、HiCache 注册、hybrid SWA/SSM 兼容。 |
5.2 RadixAttention:为什么它比普通 prefix cache 更细
RadixCache 的 key 不只是 token ids,还可以携带 extra_key 命名空间,用来隔离 LoRA adapter、cache version、RAG 上下文等。匹配时会按 page_size 对齐,查找最长前缀;如果命中落在一个节点中间,tree 会 split 出精确边界,后续请求会更快命中。
--enable-cache-report,OpenAI 响应中的 usage 会返回 cached tokens 信息;压测共享系统提示或重复长 prompt,观察 TTFT 与 cached token 数是否上升。
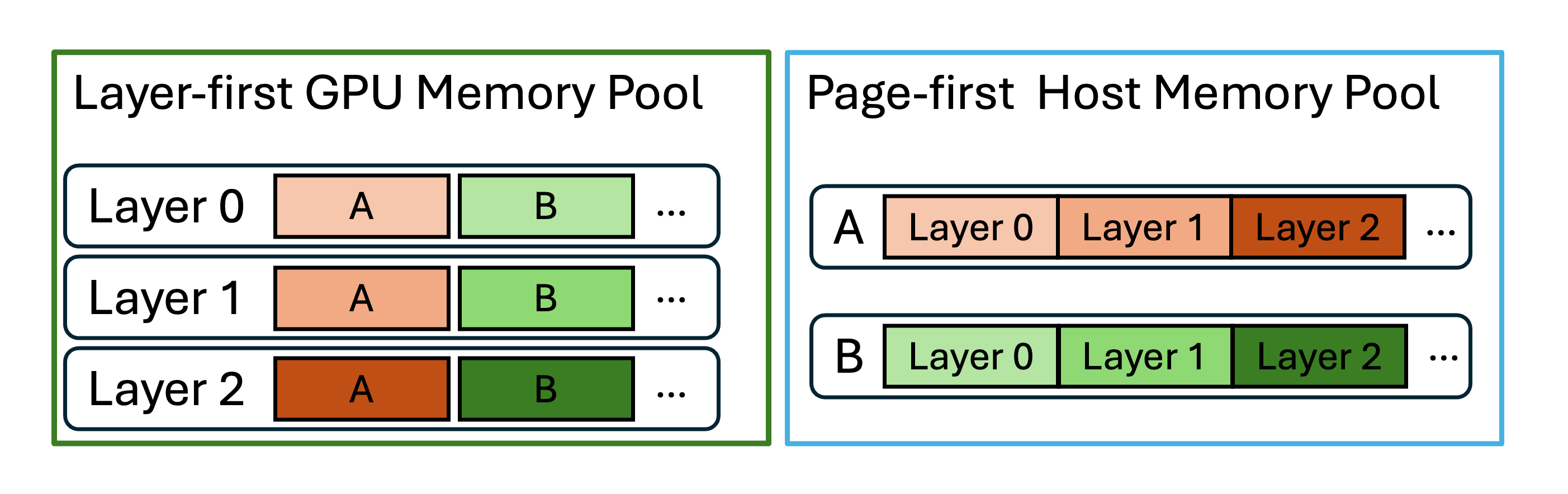
5.3 HiCache:L1 GPU、L2 Host、L3 分布式存储
HiCache 是 RadixAttention 的层级化扩展。SGLang 文档把它类比为 CPU cache:L1 是 GPU memory,本地且最快;L2 是 host memory,容量更大;L3 是跨实例共享的分布式存储,如 Mooncake、HF3FS、NIXL、AIBrix KVCache、LMCache 或 file backend。
flowchart LR
NewReq["New request tokens"] --> Local["Local match<br/>HiRadixTree"]
Local --> L1["L1 GPU KV"]
Local --> L2["L2 Host KV"]
Local --> Miss["Missed suffix"]
Miss --> Query["Query L3 metadata"]
Query --> L3["L3 Storage<br/>Mooncake / HF3FS / NIXL / AIBrix"]
L3 --> Prefetch["Prefetch to L2"]
Prefetch --> LoadGPU["CPU -> GPU transfer"]
LoadGPU --> Prefill["Prefill only missing part"]
Prefill --> Write["Write-back policy"]
Write --> L2
Write --> L3
HiCache 常用参数
python3 -m sglang.launch_server \
--model-path /models/DeepSeek-R1 \
--tp 8 \
--page-size 64 \
--enable-hierarchical-cache \
--hicache-ratio 2 \
--hicache-mem-layout page_first_direct \
--hicache-io-backend direct \
--hicache-write-policy write_through \
--hicache-storage-backend hf3fs \
--hicache-storage-prefetch-policy wait_complete \
--enable-metrics \
--enable-cache-report| 参数 | 作用 | 建议 |
|---|---|---|
--enable-hierarchical-cache |
开启 HiCache | 长上下文、多轮、共享前缀明显时开启。 |
--hicache-ratio/--hicache-size |
控制 host KV pool 容量 | --hicache-size 会覆盖 ratio;多 rank 时按每 rank 计算。 |
--hicache-storage-prefetch-policy |
L3 prefetch 停止策略 | 延迟敏感用 best_effort;命中优先用 wait_complete;生产常用 timeout 平衡。 |
--hicache-write-policy |
L1/L2/L3 写回策略 | 存储带宽充足用 write_through;热数据筛选用 write_through_selective;容量紧张用 write_back。 |
--hicache-mem-layout |
Host memory 数据布局 | 有 L3 backend 时优先评估 page_first_direct。 |
--hicache-storage-backend |
L3 backend | 可选 file、mooncake、hf3fs、nixl、aibrix、dynamic。 |
6. 集中式部署:先跑稳,再拆复杂架构
集中式部署指 prefill 与 decode 在同一个 SGLang engine 内统一调度。它部署简单、链路短、故障面小,是迁移第一站。缺点是长 prompt prefill 会打断 decode,DP Attention 下不同 DP worker 可能处理不同阶段,导致 decode latency 抖动。
6.1 安装与容器
# 推荐 uv 安装
pip install --upgrade pip
pip install uv
uv pip install sglang
# 开发源码安装
git clone https://github.com/sgl-project/sglang
cd sglang
pip install -e "python"
# Docker 运行示例
docker run --gpus all \
--shm-size 32g \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
--env "HF_TOKEN=<secret>" \
--ipc=host \
lmsysorg/sglang:latest-runtime \
python3 -m sglang.launch_server \
--model-path meta-llama/Llama-3.1-8B-Instruct \
--host 0.0.0.0 \
--port 300006.2 单机多卡 DeepSeek / GLM 模板
DeepSeek V3/R1
python3 -m sglang.launch_server \
--model-path deepseek-ai/DeepSeek-R1 \
--tp 8 \
--trust-remote-code \
--host 0.0.0.0 \
--port 30000 \
--mem-fraction-static 0.90 \
--enable-metrics \
--enable-cache-reportGLM-4.6 FP8
python3 -m sglang.launch_server \
--model zai-org/GLM-4.6-FP8 \
--tp 8 \
--tool-call-parser glm45 \
--reasoning-parser glm45 \
--host 0.0.0.0 \
--port 30000 \
--mem-fraction-static 0.906.3 OpenAI SDK 请求
from openai import OpenAI
client = OpenAI(base_url="http://127.0.0.1:30000/v1", api_key="EMPTY")
resp = client.chat.completions.create(
model="deepseek-ai/DeepSeek-R1",
messages=[
{"role": "system", "content": "你是一个严谨的推理助手。"},
{"role": "user", "content": "解释一下 SGLang 的 RadixCache。"},
],
temperature=0.2,
max_tokens=1024,
)
print(resp.choices[0].message)6.4 Router 多 worker 集中式服务
如果模型可复制,可以启动多个 regular worker,用 SGLang Model Gateway / Router 做负载均衡。策略可选 random、round_robin、power_of_two、cache_aware、bucket。共享前缀多时优先评估 cache_aware。
# Worker 1
python -m sglang.launch_server \
--model meta-llama/Llama-3.1-8B-Instruct \
--host 0.0.0.0 \
--port 8000
# Worker 2
python -m sglang.launch_server \
--model meta-llama/Llama-3.1-8B-Instruct \
--host 0.0.0.0 \
--port 8001
# Router
python -m sglang_router.launch_router \
--worker-urls http://worker1:8000 http://worker2:8001 \
--policy cache_aware \
--host 0.0.0.0 \
--port 300007. PD 分离式部署:Prefill 与 Decode 各干各的活
LLM 推理有两个阶段:prefill 处理整个输入序列,计算密集;decode 每次生成一个 token,内存带宽和 KV cache 访问密集。集中式调度把两者混在一起,会出现 prefill 打断 decode、DP Attention worker 阶段不均衡等问题。PD Disaggregation 就是把 prefill worker 和 decode worker 拆开,用 KV transfer backend 连接。
flowchart LR
Client["Client"] --> Router["SGLang Router<br/>--pd-disaggregation"]
Router --> P1["Prefill worker A<br/>compute prompt KV"]
Router --> P2["Prefill worker B<br/>cache-aware optional"]
P1 --> Transfer["KV transfer backend<br/>Mooncake / NIXL / Ascend"]
P2 --> Transfer
Transfer --> D1["Decode worker A<br/>receive KV + generate"]
Transfer --> D2["Decode worker B<br/>receive KV + generate"]
D1 --> Router
D2 --> Router
Router --> Client
7.1 什么时候值得上 PD
| 场景 | 集中式表现 | PD 分离收益 | 风险 |
|---|---|---|---|
| 长 prompt + 长输出混合 | prefill 抢占 decode,TPOT 抖动 | decode worker 更稳定,prefill 可独立扩容 | KV 传输成为新瓶颈。 |
| DeepSeek/GLM MoE 大模型高并发 | DP Attention 下阶段不均衡明显 | prefill/decode 分别调 batch、并行与显存 | 并行配置、bootstrap、router 更复杂。 |
| 多租户或不同 SLO | 请求类型相互干扰 | 可给 prefill/decode 不同硬件池和路由策略 | 需要完整指标和容量规划。 |
| 固定系统提示多、长文档 QA | 本地 prefix cache 受单实例限制 | 配合 HiCache/L3 可跨实例复用 | 缓存一致性和存储带宽要验证。 |
7.2 单机 Llama PD 最小示例
# Prefill worker
python -m sglang.launch_server \
--model-path meta-llama/Llama-3.1-8B-Instruct \
--disaggregation-mode prefill \
--port 30000 \
--disaggregation-ib-device mlx5_roce0
# Decode worker
python -m sglang.launch_server \
--model-path meta-llama/Llama-3.1-8B-Instruct \
--disaggregation-mode decode \
--port 30001 \
--base-gpu-id 1 \
--disaggregation-ib-device mlx5_roce0
# Router
python -m sglang_router.launch_router \
--pd-disaggregation \
--prefill http://127.0.0.1:30000 \
--decode http://127.0.0.1:30001 \
--host 0.0.0.0 \
--port 80007.3 DeepSeek V3.2 / GLM-5 PD 模板
# Prefill
python -m sglang.launch_server \
--model-path deepseek-ai/DeepSeek-V3.2-Exp \
--disaggregation-mode prefill \
--host ${LOCAL_IP} \
--port ${PREFILL_PORT} \
--tp 8 \
--dp 8 \
--enable-dp-attention \
--dist-init-addr ${HOST}:${DIST_PORT} \
--trust-remote-code \
--disaggregation-bootstrap-port 8998 \
--mem-fraction-static 0.9
# Decode
python -m sglang.launch_server \
--model-path deepseek-ai/DeepSeek-V3.2-Exp \
--disaggregation-mode decode \
--host ${LOCAL_IP} \
--port ${DECODE_PORT} \
--tp 8 \
--dp 8 \
--enable-dp-attention \
--dist-init-addr ${HOST}:${DIST_PORT} \
--trust-remote-code \
--mem-fraction-static 0.9
# Router
python -m sglang_router.launch_router \
--pd-disaggregation \
--prefill ${PREFILL_ADDR} 8998 \
--decode ${DECODE_ADDR} \
--host 0.0.0.0 \
--port 80007.4 Transfer backend:Mooncake、NIXL、Ascend
| Backend | 安装/参数 | 适合场景 | 关键注意点 |
|---|---|---|---|
| Mooncake | uv pip install mooncake-transfer-engine--disaggregation-transfer-backend mooncake 或默认相关路径 |
RDMA/NVLink 高性能 KV transfer,DeepSeek 多节点示例丰富 | 配置 IB device、NVLink mem pool、thread pool、queue size、timeout。 |
| NIXL | pip install nixl--disaggregation-transfer-backend nixl |
UCX/LIBFABRIC/插件化传输 | 通过 SGLANG_DISAGGREGATION_NIXL_BACKEND 选择 UCX 或 LIBFABRIC。 |
| Ascend | --disaggregation-transfer-backend ascend |
昇腾 NPU 部署 | 需要 memfabric_hybrid、ASCEND_MF_STORE_URL、ASCEND_NPU_PHY_ID 等环境变量。 |
| Fake | --disaggregation-transfer-backend fake |
decode-only benchmark 或链路开发调试 | 不能代表真实 KV 传输性能。 |
7.5 PD 内部源码流程
当前源码中,Scheduler 混入了 SchedulerDisaggregationPrefillMixin 和 SchedulerDisaggregationDecodeMixin。Prefill event loop 会接收请求、等待 bootstrap 完成、生成 prefill batch、run batch,然后把 KV transfer 任务放入 inflight queue;Decode event loop 会处理 decode queue、构造 prebuilt batch、把已经收到 KV 的请求合并进 running batch,然后逐 token decode。
sequenceDiagram
participant R as Router
participant P as Prefill Scheduler
participant T as Transfer Backend
participant D as Decode Scheduler
participant C as Client
C->>R: chat/completions
R->>P: request + bootstrap metadata
R->>D: preallocate / decode metadata
P->>P: tokenize handled earlier, schedule prefill batch
P->>P: forward_extend, build KV
P->>T: send KV pages / indices
T->>D: KV ready
D->>D: build prebuilt batch
D->>D: forward_decode loop
D->>R: streamed tokens
R->>C: SSE / response
8. HiCache + PD:长上下文生产部署的组合拳
PD 解决阶段干扰,HiCache 解决缓存容量和跨实例复用。SGLang 官方最佳实践给出两种组合:只在 prefill 节点启用 HiCache,适合系统提示/模板复用;或在 prefill 节点启用 HiCache,并在 decode 节点开启异步 KV offload,让多轮对话里的 decode 产物也回流到 L3,供后续 prefill 复用。
flowchart TD
subgraph P["Prefill Cluster"]
P1["Prefill worker 1<br/>HiCache enabled"]
P2["Prefill worker 2<br/>HiCache enabled"]
end
subgraph D["Decode Cluster"]
D1["Decode worker 1<br/>optional async offload"]
D2["Decode worker 2<br/>optional async offload"]
end
subgraph L3["Shared L3 KV Storage"]
S1["HF3FS / Mooncake / NIXL / AIBrix"]
end
P1 <--> S1
P2 <--> S1
D1 -->|write-back dialogue KV| S1
D2 -->|write-back dialogue KV| S1
P1 -->|PD transfer| D1
P2 -->|PD transfer| D2
8.1 Prefill-only HiCache
python3 -m sglang.launch_server \
--model-path /models/DeepSeek-R1 \
--tp 8 \
--host 0.0.0.0 \
--port 10000 \
--enable-metrics \
--enable-cache-report \
--mem-fraction-static 0.85 \
--page-size 64 \
--enable-hierarchical-cache \
--hicache-ratio 2 \
--hicache-mem-layout page_first_direct \
--hicache-io-backend direct \
--hicache-write-policy write_through \
--hicache-storage-backend hf3fs \
--hicache-storage-prefetch-policy wait_complete \
--disaggregation-ib-device mlx5_0 \
--disaggregation-mode prefill \
--disaggregation-transfer-backend mooncake8.2 Decode async offload
python3 -m sglang.launch_server \
--model-path /models/DeepSeek-R1 \
--tp 8 \
--host 0.0.0.0 \
--port 10001 \
--enable-metrics \
--enable-cache-report \
--page-size 64 \
--hicache-ratio 2 \
--hicache-mem-layout page_first_direct \
--hicache-io-backend direct \
--hicache-write-policy write_through \
--hicache-storage-backend hf3fs \
--hicache-storage-prefetch-policy wait_complete \
--disaggregation-decode-enable-offload-kvcache \
--disaggregation-ib-device mlx5_0 \
--disaggregation-mode decode \
--disaggregation-transfer-backend mooncake8.3 选择策略
| 工作负载 | 推荐缓存策略 | 原因 |
|---|---|---|
| 固定 system prompt + 短用户问题 | RadixCache + router cache_aware;必要时 prefill-only HiCache | prefix 重复度高,本地或跨 prefill worker 复用即可。 |
| 长文档多轮 QA | HiCache + timeout/wait_complete prefetch | 长 prefix KV 昂贵,L2/L3 可显著降低重复 prefill。 |
| 多轮对话很多,decode 生成内容也会成为下轮上下文 | Prefill HiCache + decode offload | decode 新增 KV 可以回写到 L3,下轮 prefill 直接复用。 |
| 极低延迟在线聊天 | RadixCache,小心使用 L3 wait_complete | L3 prefetch 等待可能拉高 TTFT;优先 best_effort 或 timeout。 |
9. 性能调优、压测与观测
SGLang 的调优核心是让 GPU 尽可能满,又不把 KV cache 撑爆。观察点包括 #running-req、#queue-req、token usage、TTFT、TPOT、ITL、decode throughput、OOM/retract 日志、cache hit、router worker load。
9.1 压测工具怎么选
| 工具 | 经过 HTTP? | 经过 Scheduler? | 用途 |
|---|---|---|---|
bench_serving |
是 | 是 | 默认首选,测真实在线服务 TTFT/TPOT/ITL/throughput。 |
bench_one_batch_server |
是 | 是 | 端到端单 batch 延迟,非稳态,适合快速比较。 |
bench_offline_throughput |
否 | 是 | 绕过 HTTP,测 engine 最大吞吐。 |
bench_one_batch |
否 | 否 | 直接调用 ModelRunner,做 kernel/forward profiling。 |
# 在线服务稳态压测
python3 -m sglang.bench_serving \
--backend sglang \
--host 127.0.0.1 \
--port 30000 \
--dataset-name random \
--random-input-len 2048 \
--random-output-len 512 \
--num-prompts 1000 \
--max-concurrency 100
# 低并发延迟敏感压测
python3 -m sglang.bench_serving \
--backend sglang \
--host 127.0.0.1 \
--port 30000 \
--dataset-name random \
--num-prompts 10 \
--max-concurrency 1
# Kernel/forward 级 profiling
python3 -m sglang.bench_one_batch \
--model-path meta-llama/Llama-3.1-8B-Instruct \
--batch-size 32 \
--input-len 256 \
--output-len 32 \
--profile9.2 调参口诀
吞吐优先
- 提高并发,让
#queue-req保持非零。 - 让
token usage接近但不要长期爆满。 - 增大
--mem-fraction-static扩 KV pool,但保留 5-8GB activation 空间作为经验起点。 - 能 DP 就优先 DP 或 router 多 worker;DeepSeek 高并发评估 DP Attention。
- 共享前缀多时尝试
--schedule-policy lpm或 routercache_aware。
延迟优先
- 降低
--max-running-requests,避免过大 batch 拉高单请求延迟。 - 长 prompt OOM 时降
--chunked-prefill-size。 - 小 batch 可评估 CUDA Graph、torch.compile、EAGLE。
- PD 场景分别压 prefill 和 decode,decode TPOT 比总 throughput 更重要。
- HiCache L3 prefetch 用 best_effort 或 timeout,避免过度等待。
9.3 PD profiler
# Profile prefill workers
python -m sglang.bench_serving \
--backend sglang \
--model meta-llama/Llama-3.1-8B-Instruct \
--num-prompts 10 \
--sharegpt-output-len 100 \
--profile \
--pd-separated \
--profile-prefill-url http://127.0.0.1:30000
# Profile decode workers
python -m sglang.bench_serving \
--backend sglang \
--model meta-llama/Llama-3.1-8B-Instruct \
--num-prompts 10 \
--sharegpt-output-len 100 \
--profile \
--pd-separated \
--profile-decode-url http://127.0.0.1:30001--profile-prefill-url 和 --profile-decode-url 互斥。
10. 二次开发:从哪里下刀
二开 SGLang 最好按模块进入,不要一上来全局搜。你通常会改五类东西:新模型、新 attention/kernel、新 cache/storage backend、新调度/路由策略、新 parser/API。
10.1 源码地图
| 目标 | 主要目录/文件 | 你会改什么 |
|---|---|---|
| 新增文本模型 | python/sglang/srt/models/python/sglang/srt/models/registry.py |
添加模型文件、实现 forward、EntryClass、使用 RadixAttention 和 SGLang layers。 |
| 新增多模态模型 | srt/multimodal/processors/srt/configs/model_config.pysrt/models/*_vl.py |
注册 multimodal、处理 chat template、实现 processor、pad_input_ids、get_image_feature、VisionAttention。 |
| 新增 cache backend | srt/mem_cache/hicache_storage.pysrt/mem_cache/storage/backend_factory.py |
实现 batch_exists/get/set,或用 dynamic backend 指定 module/class。 |
| 改调度策略 | srt/managers/scheduler.pysrt/managers/schedule_policy.pysrt/managers/schedule_batch.py |
等待队列排序、batch 构造、preemption、priority、chunked prefill、decode 更新。 |
| 改模型执行 | srt/model_executor/model_runner.pysrt/layers/attention/ |
forward_extend/forward_decode、attention metadata、CUDA Graph、backend dispatch。 |
| PD 传输扩展 | srt/disaggregation/ |
transfer backend、bootstrap、decode prealloc、staging buffer、offload manager。 |
| OpenAI/parser 扩展 | srt/entrypoints/openai/srt/function_call/srt/parser/ |
reasoning parser、tool call parser、chat template、协议字段。 |
| Router 策略 | SGLang Model Gateway / sglang_router |
worker 注册、健康检查、cache-aware、power_of_two、PD 路由、IGW 多模型。 |
10.2 新模型接入流程
flowchart TD
A["选择相似模型实现<br/>如 llama.py / qwen*.py / deepseek*.py"] --> B["复制到 srt/models/new_model.py"]
B --> C["替换 Attention 为 RadixAttention<br/>替换 logits processor / layers"]
C --> D["实现 forward / forward_batch<br/>支持 ForwardBatch"]
D --> E["添加 EntryClass / registry"]
E --> F["bench_one_batch --correct<br/>对齐 HF logits/output"]
F --> G["OpenAI server 测试"]
G --> H["加入 registered tests<br/>报告硬件、启动参数、准确率、吞吐"]
# 外部注册模型的最小思路:不改 SGLang 源码也可以先注册
from sglang.srt.models.registry import ModelRegistry
from sglang.srt.entrypoints.http_server import launch_server
from my_model_impl import MyForCausalLM
ModelRegistry.models["MyForCausalLM"] = MyForCausalLM
# 然后用你的 ServerArgs 启动
# launch_server(server_args)10.3 自定义 HiCache storage backend
如果你已有内部 KV 存储、对象存储或 RDMA cache 系统,可以实现 HiCacheStorage。最核心接口是 batch exists/get/set;如果不想硬编码进仓库,可使用 dynamic backend。
python3 -m sglang.launch_server \
--model-path your-model \
--enable-hierarchical-cache \
--hicache-storage-backend dynamic \
--hicache-storage-backend-extra-config \
'{"backend_name":"corp_cache","module_path":"corp.sglang_cache","class_name":"CorpHiCacheStorage","interface_v1":0}'10.4 修改调度的注意事项
- Scheduler 的数据结构很多是为 overlap schedule、chunked prefill、spec decoding、PD mode 共同服务的,改 batch 生命周期时必须同时看 normal 和 overlap loop。
- cache 相关字段如
prefix_indices、kv_committed_len、cache_protected_len、last_node会影响 free/evict,不能只看 forward 结果。 - PD decode 侧有 prebuilt batch 与 preallocated KV 的特殊路径,源码里明确避免重新 match prefix,因为树状态可能已变化,错误更新会导致释放范围不正确。
- 新增策略后至少跑:普通集中式、chunked prefill、RadixCache hit、PD prefill/decode、abort/timeout、priority、spec decoding 组合测试。
10.5 推荐测试命令
# 对齐 HF 输出和 prefill logits
python3 scripts/playground/reference_hf.py \
--model-path /path/to/new-model \
--model-type text
python3 -m sglang.bench_one_batch \
--correct \
--model /path/to/new-model
# 注册模型测试示例
ONLY_RUN=Qwen/Qwen2-1.5B \
python3 -m unittest test_generation_models.TestGenerationModels.test_others
# 准确率评估
python -m sglang.test.run_eval \
--eval-name mmlu \
--port 30000 \
--num-examples 1000 \
--max-tokens 819211. 生产落地清单
上线前
- 固定 SGLang 版本、Docker tag、模型 revision、启动参数。
- 离线下载权重,校验 tokenizer、chat template、reasoning/tool parser。
- 先集中式压测,再决定是否拆 PD。
- 为每类请求设定 max input/output token、timeout、队列上限。
- 开启 metrics、cache report、结构化日志,保留 crash dump 策略。
上线后
- 持续看 TTFT、TPOT、ITL、E2E latency、queue length、token usage。
- 记录 cache hit、cached tokens、HiCache prefetch latency、L3 read/write 带宽。
- PD 模式分别监控 prefill、decode、transfer backend、router。
- OOM 时先区分 prefill OOM 还是 decode OOM,再调 chunked prefill、max-running、mem fraction。
- 新模型或新 backend 合入前必须给出 accuracy、latency、throughput、硬件环境和启动命令。
从 0 到生产的执行路线
flowchart LR
S0["0. 选模型/硬件"] --> S1["1. 单机集中式跑通"]
S1 --> S2["2. OpenAI API 兼容验收"]
S2 --> S3["3. bench_serving 压测"]
S3 --> S4["4. 调 mem / batch / attention backend"]
S4 --> S5["5. Radix/HiCache 验证"]
S5 --> S6["6. Router 多 worker"]
S6 --> S7{"prefill/decode 干扰明显?"}
S7 -->|否| S8["集中式生产化"]
S7 -->|是| S9["PD 分离试点"]
S9 --> S10["PD + HiCache + 完整观测"]
S10 --> S11["灰度上线"]
--host 0.0.0.0、--port、--tp/--dp、--mem-fraction-static、--max-running-requests、--chunked-prefill-size、--enable-metrics、--enable-cache-report、--reasoning-parser、--tool-call-parser、--served-model-name。先把这套管住,再加更高级优化。
12. 参考资料
本报告优先使用 SGLang 官方文档、官方 GitHub 仓库与 SGLang/LMSYS 官方博客图片。由于 SGLang 更新频繁,部署生产前建议以你要使用的具体 release branch 或 Docker tag 对应文档为准。
- SGLang GitHub repository,本地调研快照 commit
6e8fe17,2026-05-25。 - SGLang Install documentation:pip/uv、source、Docker、Kubernetes、云部署安装方式。
- Server Arguments:模型、HTTP、量化、内存、调度、并行、LoRA、API、metrics 参数。
- DeepSeek V3/V3.1/R1 Usage:MLA、DP Attention、FP8、DeepGEMM、MTP/EAGLE、函数调用与 reasoning parser。
- DeepSeek V3.2 / GLM-5 Usage:DSA、IndexCache、TP+DP Attention、PD 分离启动命令。
- GLM-4.5 / GLM-4.6 / GLM-4.7 Usage:GLM FP8、EAGLE、thinking budget、tool parser。
- PD Disaggregation:Mooncake、NIXL、Ascend backend、环境变量、heterogeneous TP staging buffer。
- HiCache System Design and Optimization:HiRadixTree、local match、prefetch、write-back、L3 backend、PD 集成。
- SGLang HiCache Best Practices:核心参数、PD 组合、HF3FS/Mooncake 示例、自定义 storage backend。
- Attention Backend:MHA/MLA/DSA backend 支持矩阵、page size、FP8/FP4、spec decoding 兼容性。
- Supported Text Generation Models:DeepSeek、GLM、Qwen、Llama、Kimi、GPT-OSS 等模型族。
- Supported Multimodal Language Models:Qwen-VL、DeepSeek-OCR、GLM-4.5V、Qwen3-ASR、GLM-OCR 等。
- How to Support New Models:新增 LLM/MLLM、从 vLLM port、外部注册、测试方法。
- Transformers fallback in SGLang:Transformers backend fallback 条件与远程代码支持。
- SGLang Model Gateway:router、PD routing、load balancing、worker 管理、IGW、观测与可靠性。
- Benchmark and Profiling:bench_serving、bench_one_batch、PD profiler、HTTP profiling endpoints。
- Evaluating New Models with SGLang:MMLU、GSM8K、GPQA、MMMU、latency/throughput benchmark。
- SGLang v0.3 LMSYS blog:DeepSeek MLA 优化图片来源。
- SGLang v0.4 LMSYS blog:DP Attention 图片来源。
- SGLang HiCache LMSYS blog:HiCache overview/layout 图片来源。